

개요
데브코스 팀원들과 웹툰 서비스를 주제로 사이드 프로젝트를 경험했다. 이 프로젝트를 무사히 마치고 나서 다음과 같은 의문이 들었다. "사용자들은 유료 웹툰을 구매하기 위에 쿠키라는 상품을 사용하는데, 만약 동일한 아이디로 다른 사용자가 동시에 유료 웹툰을 구매하면 어떻게 될까?" 이 의문을 해소하고자 포스팅을 작성하게 되었다.
❗️ 문제
사용 가능한 쿠키가 100개가 있고, 동일한 아이디로 동시에 다른 유료 웹툰을 구매했다고 가정하자.
Race Condition (경쟁 상태) : 둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태
개발 관점으로 보면 두 명의 사용자가 쿠키에 동시에 접근하여 쿠키 갯수를 감소시킬 수 있게 된다. 즉, 쿠키 갯수라는 공유 자원에 2명의 사용자가 접근하여 읽거나 쓰려고 하는 Race Condition이 발생할 수 있게 되는 것이다.
이를 직접 눈으로 보기 위해 간단한 동시성 이슈를 경험할 프로젝트를 만들고 성능 테스트 도구인 NGrinder 활용해, 1000명의 사용자가 동시에 유료 웹툰을 구매하여 쿠키 갯수가 감소하는 API를 직접 호출해보자. (물론 이런 경우는 없겠지만..ㅎ)
문제 상황
[현재 쿠키 갯수 : 10_000개]

[1_000명의 사용자 동시에 1개의 쿠키가 필요한 유료 웹툰 구매]
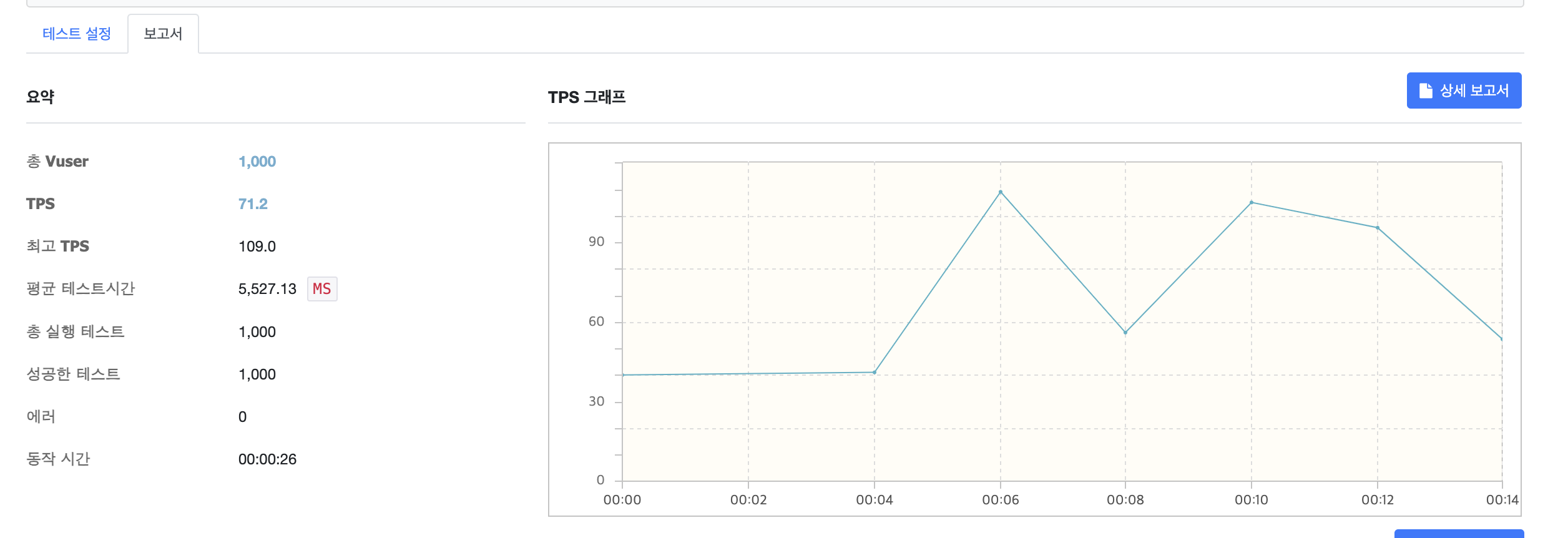
[유로 웹툰 구매 후 쿠키 갯수 : 9_936개]

테스트 실행 후 NGrinder 보고서를 보면 성공한 테스트는 1_000건이라고 나온다. 하지만 실제 데이터베이스의 쿠키 갯수를 보면 9936개가 존재한다. 1000개를 사용해서 총 9000개가 되어야 하는데 말이다.
문제 원인
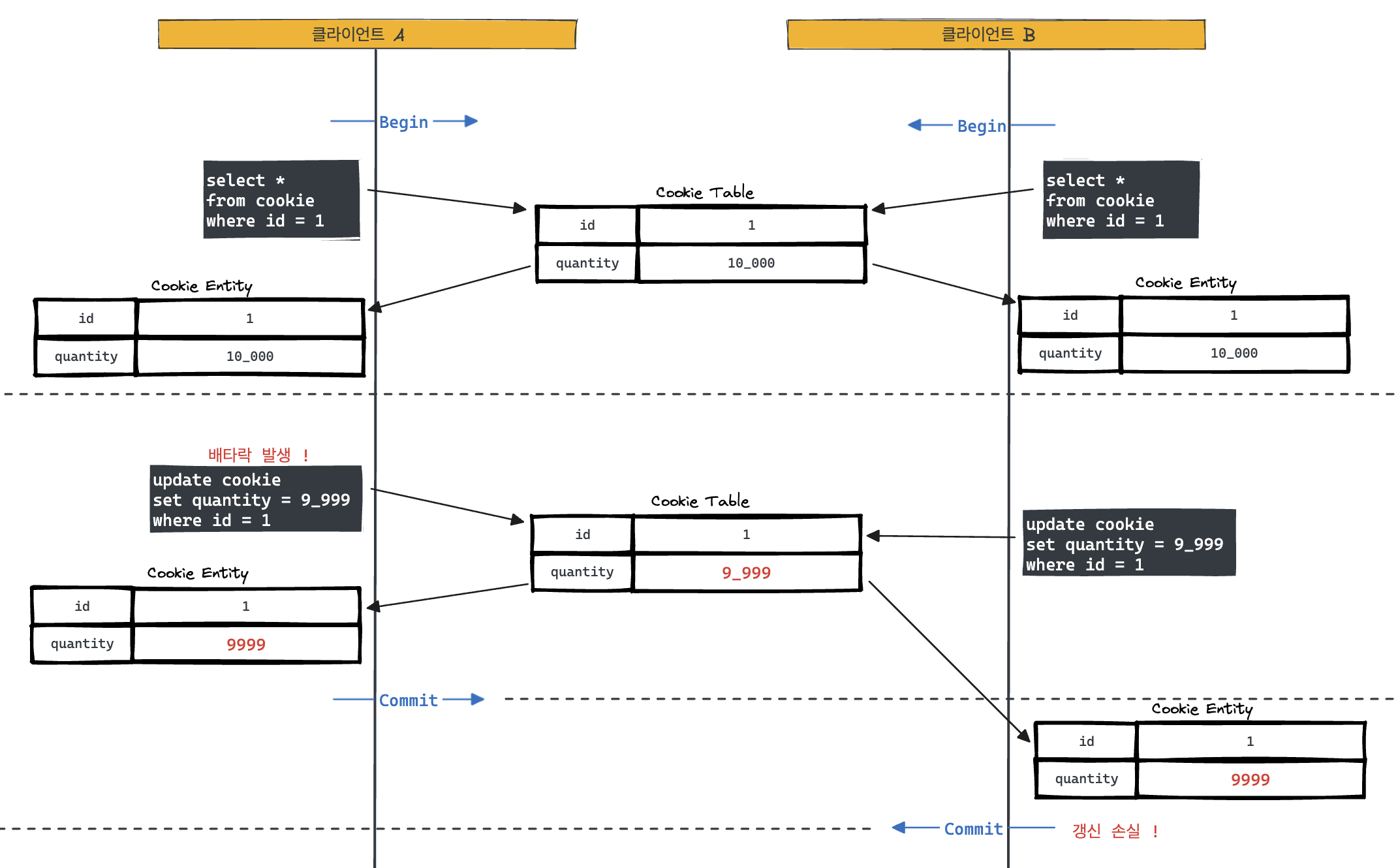
위 그림처럼 클라이언트 A, B가 동시에 id가 1 데이터를 읽고 쿠키 갯수를 9_999개로 변경하는 쿼리를 날린다. 이처럼 2개의 트랜잭션이 하나의 데이터를 동시에 갱신하게 되고 이로 인해 갱신 손실이 발생하는 것이다.
문제 해결 (Java 활용)
자바의 synchronized 키워드를 이용하기 (실패)
public synchronized void decrease(Long id, long quantity) {
Stock stock = stockRepository.findById(id)
.orElseThrow(() -> new IllegalArgumentException("not found stock by id"));
stock.decrease(quantity);
}첫 번째 방식은 위 코드와 같이 자바의 synchronized 키워드를 활용하는 것이다. 하지만 이 방식은 JPA의 @Transactional 어노테이션을 사용하는 순간 실패하게 된다.
@Transactional은 synchronized와는 다른 목적의 동작 방식으로 돌아간다. synchronized는 멀티 스레드 환경에서 단 하나의 스레드만이 특정 코드 블럭을 실행하도록 보장하는 역할을 하는 것으로 메모리 내 데이터의 동시 접근에 대한 안정성을 보장하지만 @Transactional은 선언된 메서드를 데이터베이스 트랜잭션 범위 내에서 실행하도록 보장한다. 그리고 @Transactional은 AOP기반이기 때문에 synchronized가 생성된 AOP 프록시 객체 내부에서만 유효하게 된다.
문제 해결 (MySQL 활용)
낙관적 락 (Optimistic Lock)
두 번째 방식으로는 낙관적 락이다. 낙관적 락은 실제로 락을 이용하지 않고 버전을 이용함으로써 정합성을 맞추는 방법이다. 즉, DB에 직접적으로 락을 걸지 않고, 충돌(동시성) 문제가 발생하면 그때 처리하는 방식이다. 때문에, 충돌이 거의 발생하지 않는 상황에서 충돌이 발생한다면 그때 대비하는 방식이라고 할 수 있다.
[ 낙관적 락 흐름 ]
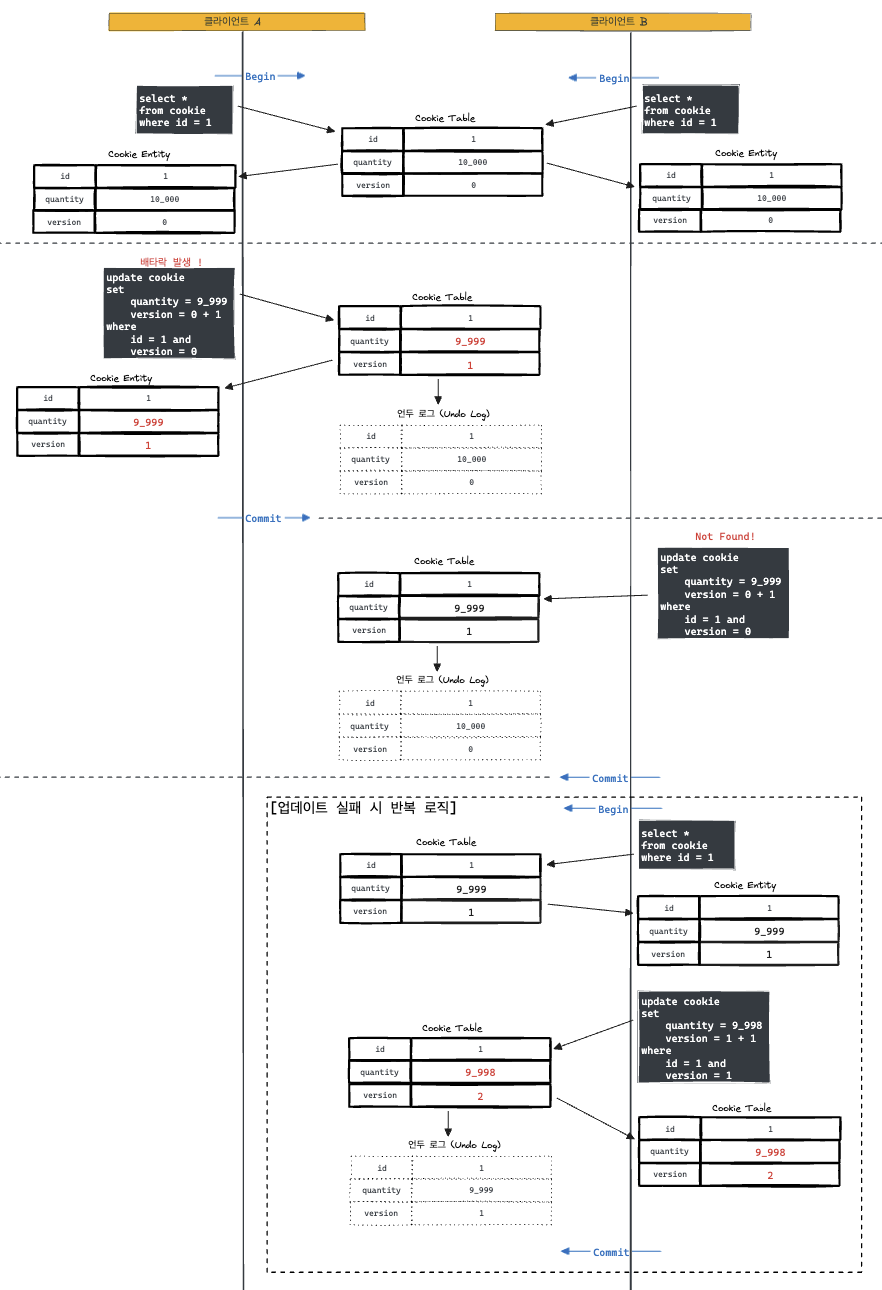
위 그림처럼 미세하지만 조금 더 빨랐던 클라이언트가 더 빠르게 쿠키 갯수를 -1 하고 동시에 버전 정보를 +1 하고 커밋한다. 그리고 더 느렸던 클라이언트가 이어서 -1을 하고 업데이트를 하는데, 이때 버전 정보가 달라졌기 때문에, 업데이트가 실패하고 예외가 발생하게 된다.
예외가 발생했다면 해당 서비스를 호출한 퍼사드 클래스에서 다시 조회 후 업데이트를 반복한다. 이렇게 동시성 이슈를 해결할 수 있게 된다.
[ Repository 구현 코드 ]
@Lock(LockModeType.OPTIMISTIC)
@Query("select s from Stock s where s.id = :id")
Optional<Stock> findByIdWithOptimisticLock(Long id);[ Service 구현 코드 ]
@Transactional
public long decrease(DecreaseReq decreaseReq) {
Stock stock = stockRepository.findByIdWithOptimisticLock(decreaseReq.id())
.orElseThrow(() -> new IllegalArgumentException("not found stock by id"));
stock.decrease(decreaseReq.quantity());
return stock.getQuantity();
}[ Facade 구현 코드 ]
public long decrease(DecreaseReq decreaseReq) throws InterruptedException {
while (true) {
try {
return stockService.decrease(decreaseReq);
} catch (Exception e) {
Thread.sleep(50);
}
}
}하지만 이 방식은 MySQL 환경에서 퍼사드 패턴을 이용하지 않고 하나의 클래스에서 낙관적 락을 적용한다면, MySQL의 기본 격리 수준인 Repeatable Read 때문에, 구현할 수가 없다. 왜냐하면, Repeatable Read 격리 수준에서는 select 쿼리가 실행될 때 해당 시점의 스냅샷 상태를 기반으로 결과를 반환하기 때문이다. 즉 한 트랜잭션 내에서는 동일한 select 쿼리를 여러번 실행해도 항상 동일한 결과가 반환되기 때문에, 버전으로 충돌 감지를 하는 낙관적 락을 적용할 수 없는 것이다.
그렇다고 퍼사드 패턴으로 이용하고자 하니, Service의 로직이 무거워졌을 때, 충돌이 일어나면 그 무거운 로직을 매번 실행해야 하기 때문에 좋지 않은 방법이라고 생각한다. 단 충돌이 빈번하지 않는다면 고려해보자.
비관적 락 (Pessimistic Lock)
세 번째 방식으로는 비관적 락이다. 비관적 락은 실제로 데이터에 접근하기 전 락을 걸어 충돌을 예방하는 방식이다. 즉 동시성 이슈 해결에는 확실하고 충돌이 발생할 확률이 높은 상황에서 적합하다. 하지만 락으로 인한 성능 저하, 데드락(교착 상태)이 발생할 수 있으니 주의하자.
[ 비관적 락 흐름 ]
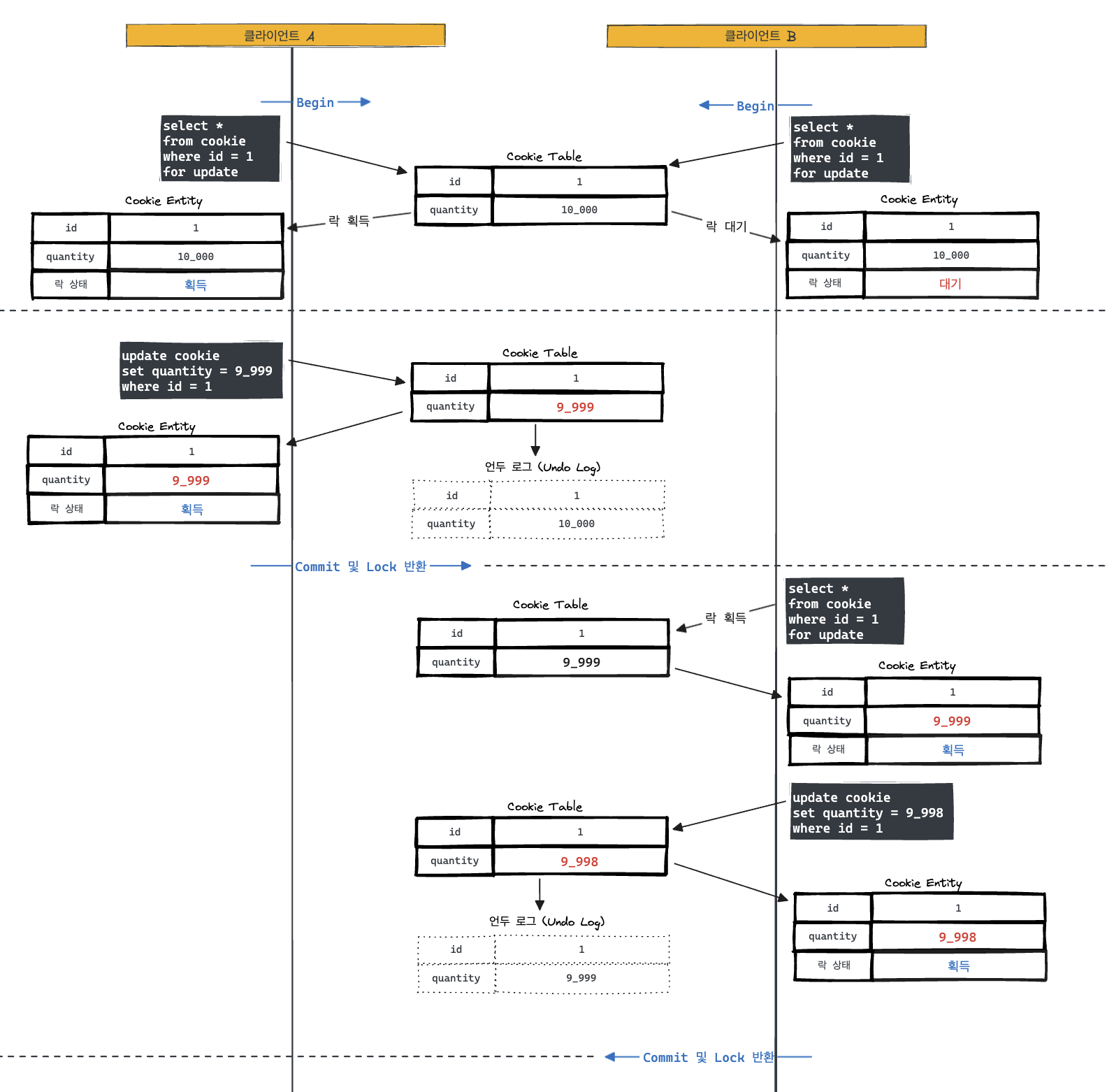
위 그림을 보면 알 수 있듯 먼저 들어온 클라이언트가 획득하며 id가 1인 데이터를 읽어오고 더 느렸던 클라이언트는 락을 획득하려 했지만 대기 상태에 진입하는 것을 볼 수 있다.
이처럼 락을 획득한 클라이언트가 먼저 쿠키 갯수를 업데이트하고 커밋이 끝났을 때, 동시에 락을 반환하고 동시에 대기하던 클라이언트가 락을 획득하여 진행되는 것을 볼 수 있다.
[ Service 구현 코드 ]
@Transactional
public long decrease(DecreaseReq decreaseReq) {
Stock stock = stockRepository.findByIdWithPessimisticLock(decreaseReq.id())
.orElseThrow(() -> new IllegalArgumentException("not found stock by id"));
stock.decrease(decreaseReq.quantity());
return stock.getQuantity();
}[ Repository 구현 코드 ]
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select s from Stock s where s.id = :id")
Optional<Stock> findByIdWithPessimisticLock(Long id);@Lock(LockModeType.PESSIMISTIC_WRITE)으로 인해 배타락이 설정되어 트랜잭션 안에서도 최신화된 데이터를 읽어올 수 있게 되어 별도로 퍼사드 클래스를 만들지 않아도 되었다. 때문에, 비관적 락은 낙관적 락에 비해 매우 간단해진다.
문제 해결 (Redis를 활용한 분산락)
Redis를 별도로 이용하면 Redis 공간이 별도로 있기 때문에 데이터베이스로 진입하기 전 미리 락을 획득하여 처리할 수 있다. 그리고 데이터베이스 뿐만 아니라 애플리케이션 서버가 스케일 아웃되더라도 동일한 Redis를 바라보고 있기 때문에 Scale-Out에 용이한 해결 방법이다.
Lettuce 유형
setnx) SET if Not eXists 줄임말로 key와 Value를 Set할 때, 기존 값이 없어야 동작하는 명령어이다.
spin lock) 락을 획득하려는 스레드가 락을 사용할 수 있는 지 반복적으로 확인하면서 락 획득을 시도하는 방식이다.
이 방식은 Redis의 setnx 명령어를 활용해 분산락을 구현하는 방식이다. setnx를 활용하면 spin lock 방식이기 때문에 재시도 로직을 개발자가 직접 작성해줘야 하고 동시에 많은 스레드가 락 획득 대기 상태라면 당연하지만 Redis에 부하를 주게 된다.
하지만 구현이 간단하고 Spring Data Redis를 활용하면 Lettuce가 기본이기 때문에, 별도 라이브러리를 사용하지 않아도 된다.
[ setnx 명령어 실습으로 살펴보기 ]
1) 키가 1인 데이터를 setnx 한다. (성공)

2) 동일한 키/값으로 재시도한다. (실패)

3) 키 1인 데이터 삭제 후 재시도 (성공)

[ Lettuce 유형 흐름 ]
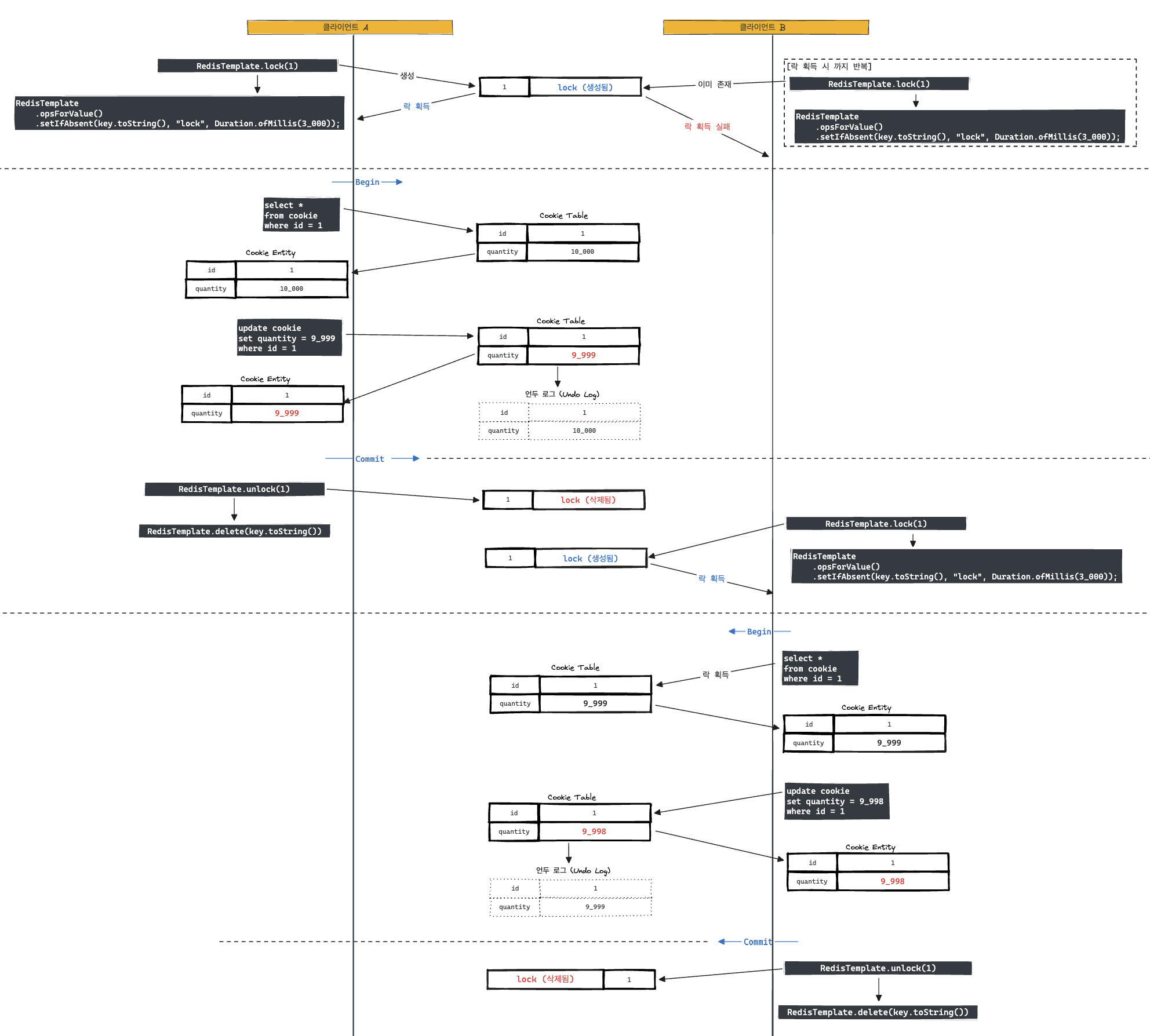
위 이미지에서 알 수 있듯 조금 더 빨랐던 클라이언트 A가 키가 1인 lock을 생성한다. 그리고 조금 더 느렸던 클라이언트는 동일한 키로 생성을 하는 데, 이미 존재하기 때문에, 해당 락 데이터가 사라질 때까지 락 획득 요청을 한다.
계속해서 클라이언트 A가 작업을 다 마친다면, 클라이언트 B가 락을 획득하고 이어서 작업을 시작한다.
[ Repository 코드 ]
@Component
@RequiredArgsConstructor
public class RedisLockRepository {
private final RedisTemplate<String, String> redisTemplate;
public Boolean lock(Long key) {
return redisTemplate.opsForValue()
.setIfAbsent(generateKey(key), "lock", Duration.ofMillis(3_000));
}
public void unlock(Long key) {
redisTemplate.delete(generateKey(key));
}
private String generateKey(Long key) {
return key.toString();
}
}[ Facade 코드 ]
public long decrease(DecreaseReq decreaseReq) throws InterruptedException {
// 만약 락 획득 실패 시, Thread.sleep을 활용해서 100텀을 두고 재시동 하도록 해야 Redis에 가는 부하를 줄여 줄 수 있다.
while (Boolean.FALSE.equals(redisLockRepository.lock(decreaseReq.id()))) {
Thread.sleep(100);
}
long quantity;
try {
quantity = stockService.decrease(decreaseReq);
} finally {
redisLockRepository.unlock(decreaseReq.id());
}
return quantity;
}Redisson 유형
이 방식은 Pub-Sub 기반으로 락 구현을 제공하는 방식으로 채널을 하나 만들고 락을 점유 중인 스레드가 락 획득을 위해 대기 중인 스레드에게 해제를 알려주면 안내를 받은 스레드가 락 획득 시도를 하는 방식이고 Pub-Sub 기반이니 Redis의 부하가 Lettuce에 비해 적다. 또 락 획득 재시도를 기본으로 제공한다.
단점으로는 Lettuce에 비해 구현이 조금 복잡하고 별도의 라이브러리를 사용해야 한다. 즉 해당 별도 라이브러리의 사용법도 공부를 해야한다.
[ publish와 subscribe 명령어 실습으로 살펴보기 ]
1) redis-cli를 2개 실행한다.

2) 첫 번째 터미널에서 subscribe 명령어를 통해 ch1을 구독하고 두 번째 터미널에서 publish 명령어를 통해 ch1 채널에 hello란 메시지를 보낸다.

이처럼 Redis를 자신이 점유하고 있는 락을 해제할 때, 채널에 메시지를 보내줌으로써 락을 획득해야 하는 스레드들에게 락을 획득하라고 전달하는 방법이다.
[ Redisson 유형 흐름 ]
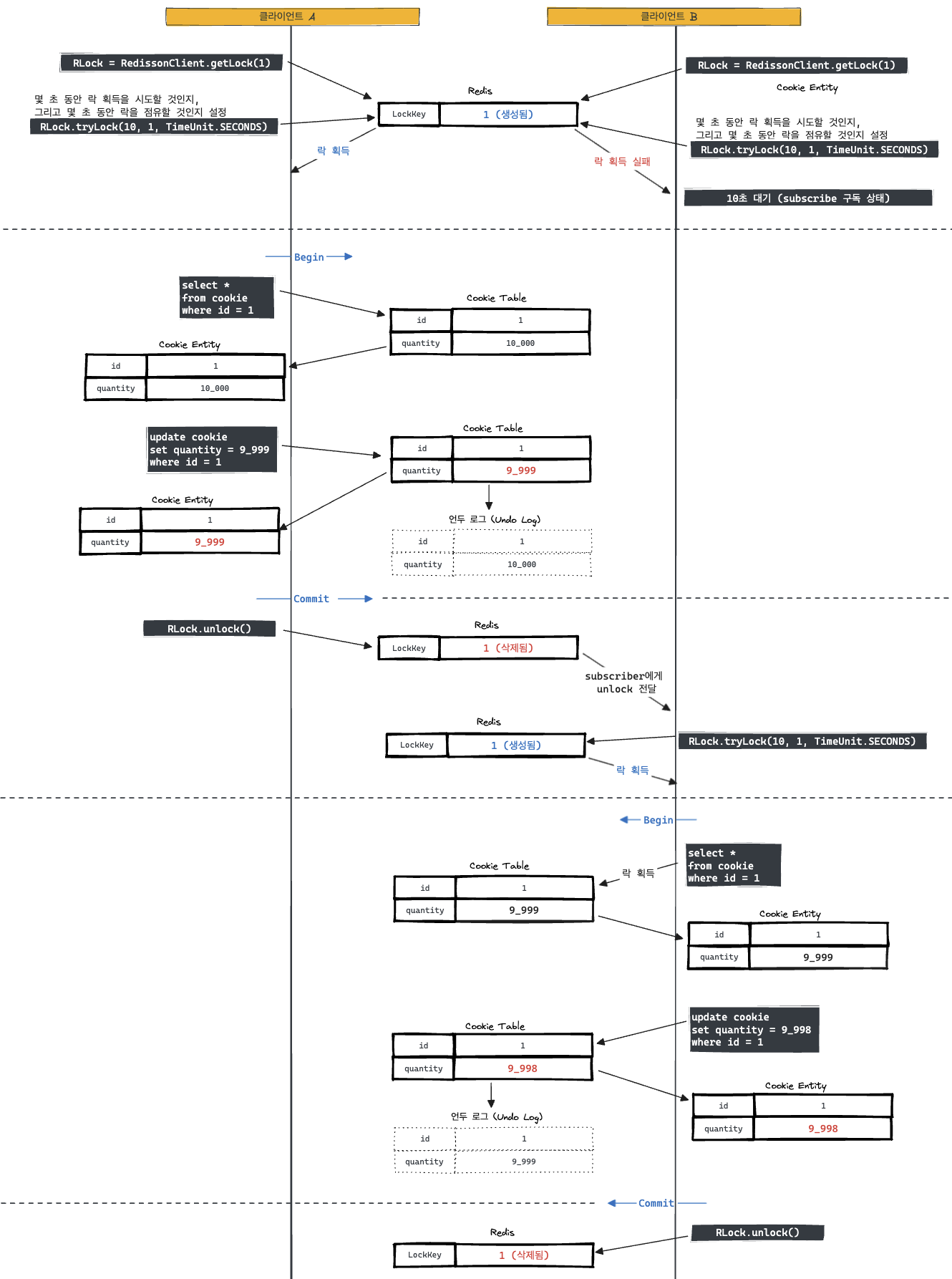
위 이미지에서 알 수 있듯 클라이언트 A에서 Redis에 쿠키 테이블 ID를 기반으로 락 획득을 요청한다. 이때 쿠키 테이블 ID인 1이 락으로 잡혀 있지 않기 때문에, 락을 획득한다. 그리고 이어서 클라이언트 B가 똑같은 값으로 락 획득을 하지만 이미 해당 값으로 락을 걸어두었기 때문에, 설정해둔 값이 10초 동안 대기 상태에 진입한다. 즉 subscribe 상태가 된다.
이제, 클라이언트 A의 작업이 시작되고 작업이 끝나면 락을 해제한다. 계속해서 Redis는 구독자에게 unlock이 되었다는 알림을 보낸다. 이제 구독자는 해당 알림을 받고 Redis에 락을 요청하여 락을 획득한다.
[ Facade 코드 ]
public long decrease(DecreaseReq decreaseReq) {
// 락 객체를 가져온다.
RLock lock = redissonClient.getLock(decreaseReq.id().toString());
boolean available = false;
long quantity = 0;
try {
// 몇 초 동안 락 획득을 시도할 것인지, 그리고 몇 초 동안 락을 점유할 것인지 설정.
available = lock.tryLock(10, 1, TimeUnit.SECONDS);
if (!available) {
throw new RuntimeException("락 획득 실패");
}
// 락 획득 시 로직 수행
quantity = stockService.decrease(decreaseReq);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
lock.unlock();
}
return quantity;
}InterruptedException 발생 시, 자바 시스템은 해당 스레드의 인터럽트 상태를 초기화한다. 때문에, 인터럽트가 발생했다는 표시를 지움 때문에 다시 인터럽트를 호출해야 한다. 즉, 예외가 발생했음에도 다시 인터럽트 상태가 유지되도록 해야 한다.
NGrinder 테스트 결과
낙관적 락 테스트 결과
[ NGrinder 보고서 ]
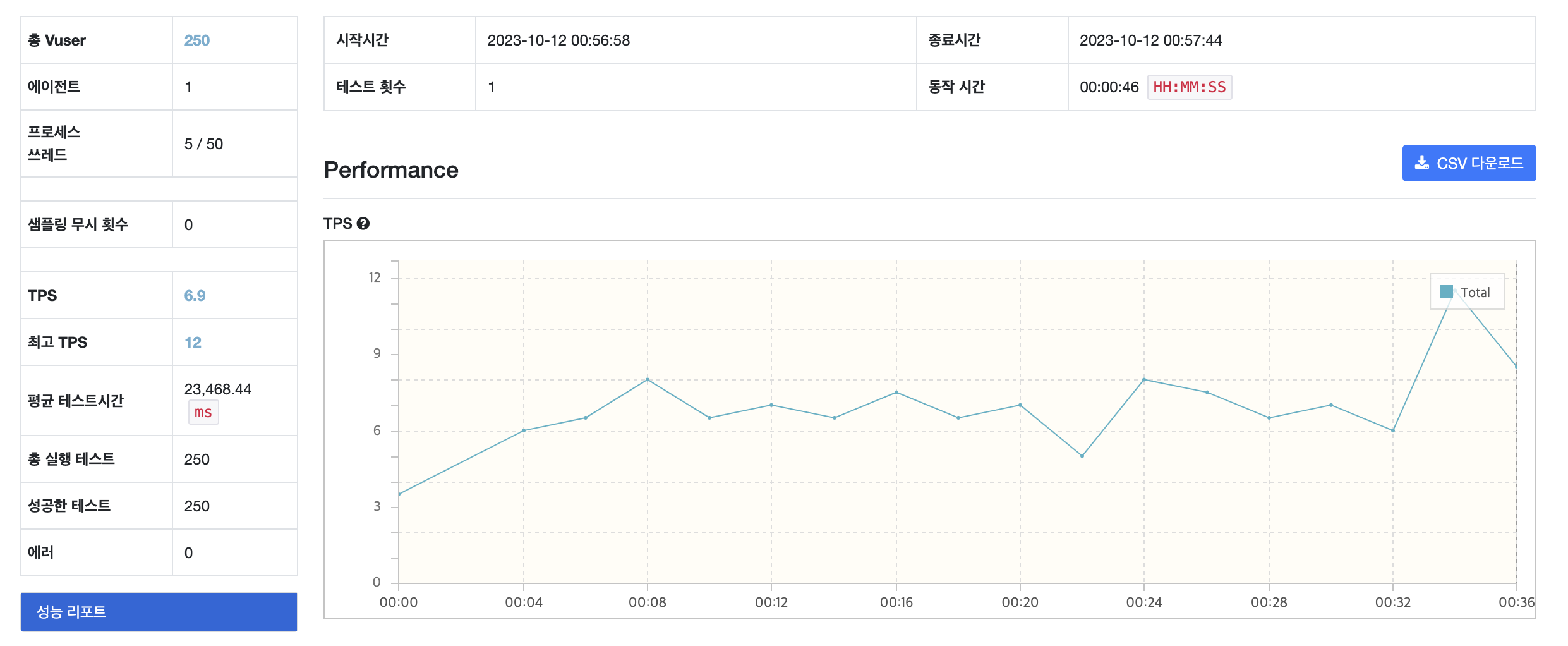
[ 테스트 전 쿠키 갯수 ]

[ 테스트 후 쿠키 갯수 ]

비관적 락 테스트 결과
[ NGrinder 보고서 ]
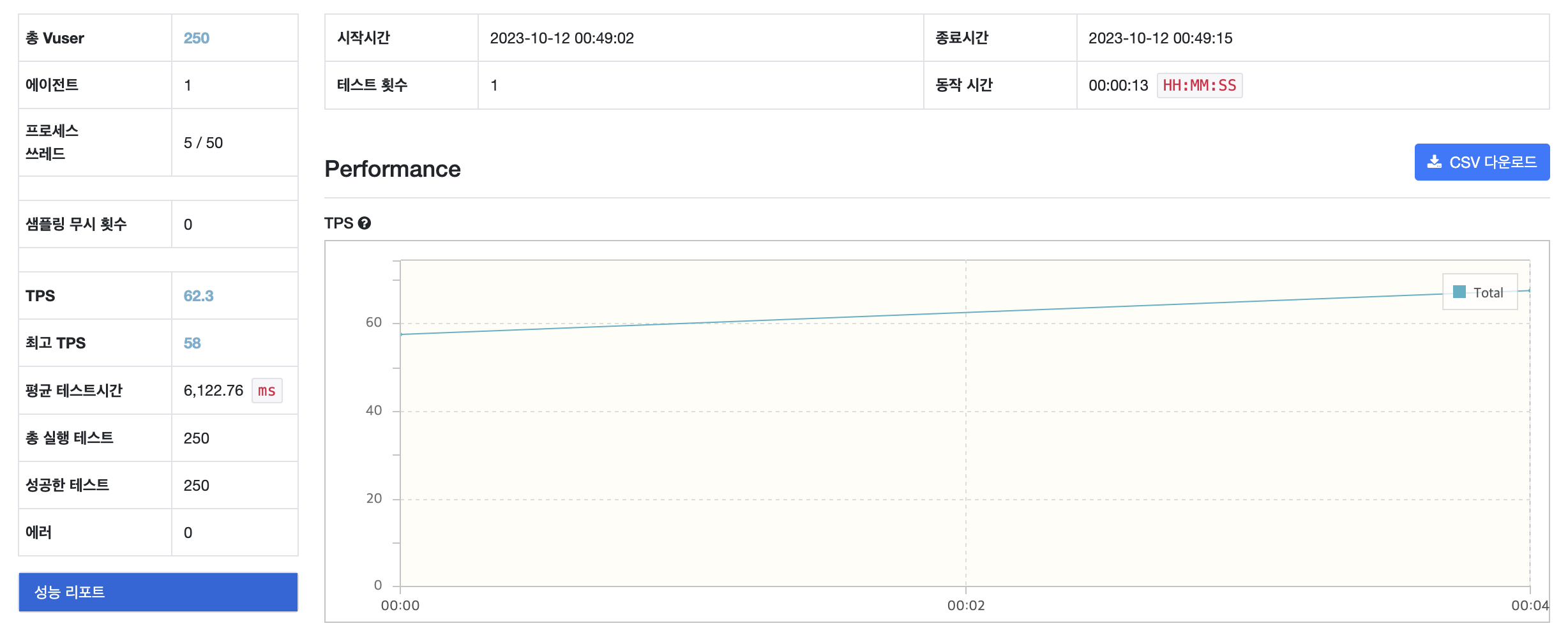
[ 테스트 전 쿠키 갯수 ]

[ 테스트 후 쿠키 갯수 ]

Redis를 활용한 Lettuce 유형 테스트 결과
[ NGrinder 보고서 ]
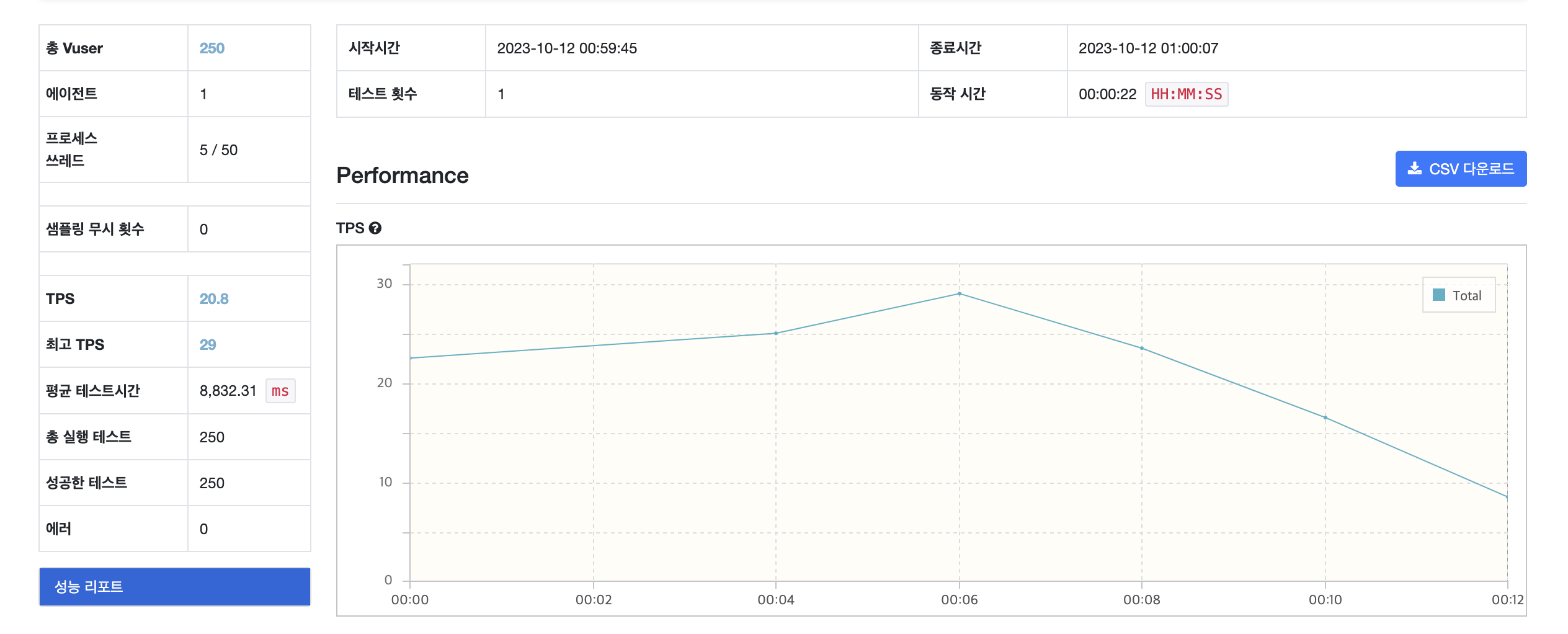
[ 테스트 전 쿠키 갯수 ]

[ 테스트 후 쿠키 갯수 ]
Redis를 활용한 Redisson 유형 테스트 결과
[ NGrinder 보고서 ]
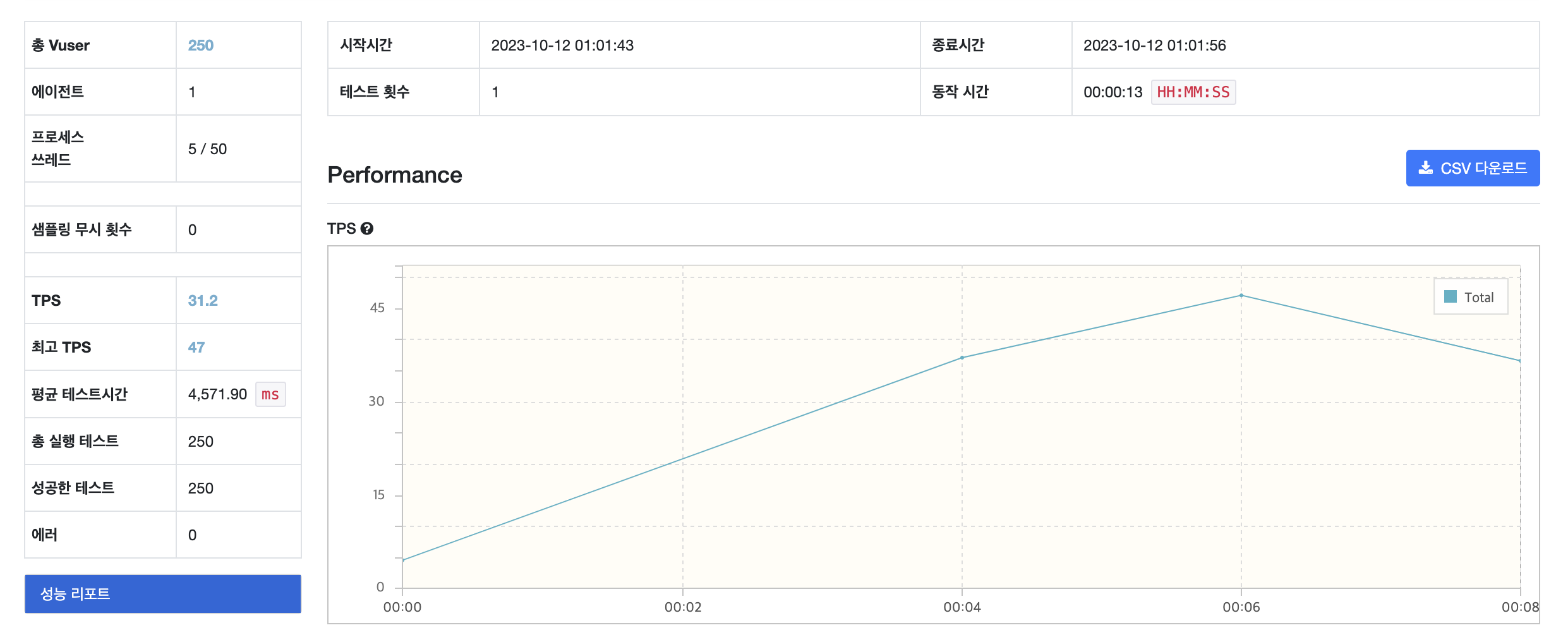
[ 테스트 전 쿠키 갯수 ]
[ 테스트 후 쿠키 갯수 ]

테스트 결과 비교 및 결론
TPS : Transactions Per Second로 초당 트랜잭션 수를 의미, 즉 시스템이 초당 처리할 수 있는 요청/응답 쌍의 수
| 낙관적 락 | 비관적 락 | Lettuce | Redisson | |
| TPS | 6.9 | 62.3 | 29.8 | 31.2 |
| 최고 TPS | 12 | 58 | 29 | 47 |
| 평균 시간 (ms) | 23,468.44 | 6,122.76 | 8,832.31 | 4,571.90 |
| 성공 요청 수 | 250 | 250 | 250 | 250 |
| 실패 요청 수 | 0 | 0 | 0 | 0 |
| 테스트 전 쿠키 갯수 | 10000 | 10000 | 10000 | 9750 |
| 테스트 후 쿠키 갯수 | 9750 | 9750 | 0750 | 9500 |
위 결과표를 보니, 충돌이 일어날 때마다 계속 요청을 해야하는 낙관적 락이 더 오래 걸리고 TPS 처리량이 낮은 것을 볼 수 있다. 그리고 비관적 락과 Redis 방식을 비교했을 때, 분명 Redis가 더 빠를 것이라 생각했지만, 그렇지도 않았다.
하지만 이 결과표는 네트워크 환경, 서버 성능 등에 따라 매번 바뀌기 때문에 유의미하다고 보기는 힘드니 가볍게 받아들여도 된다. 더 중요한 것은 어떤 상황에 어떤 잠금 메커니즘이 가장 적절한지 판단하고 사용하는 것이라 생각한다.
Reference
- Real MySQL - 개발자와 DBA를 위한 MySQL 실전 가이드 - 백은빈, 이성욱 지음
- 재고 시스템으로 알아보는 동시성 이슈 - 인프런 - 최상용
- KDT 프로그래머스 - 벡엔드 데브코스
'Activity > 데브코스 - 백엔드 엔지니어링' 카테고리의 다른 글
| 벡엔드 데브코스 TIL - 프로젝트로 단축 URL 알아가기 (0) | 2023.10.04 |
|---|---|
| 벡엔드 데브코스 TIL - 프록시 패턴 발표 (1) | 2023.07.12 |
| 백엔드 데브코스 TIL - 동행 스크럼을 하다가 공부하게 된 Process와 Thread (0) | 2023.06.12 |
| 벡엔드 데브코스 TIL - 싱글톤 패턴 발표 (4) | 2023.06.08 |
| 백엔드 데브코스 TIL - 놓치기 쉬운 JAVA 이야기 (2) | 2023.06.02 |